Object pose representation
Information about the poses and dimensions of objects is crucial for finding and manipulating them. In KnowRob, object dimensions can either be described as simple bounding boxes or cylinders (specifying the height, and either width and depth or the radius), or by linking a 3D surface mesh model in the STL or Collada format.
Object poses are described by 4×4 pose matrices. Per default, the system assumes all poses to be in the same global coordinate system. Pose matrices can, however, be qualified with a coordinate frame identifier. The robot can then transform these local poses into the global coordinate system, for example using the tf library.
Since robots act in dynamic environments, they need to be able to represent both the current world state and past beliefs. A naive approach for describing the pose of an object would be to add a property location that links the object instance to a point in space or, more general, a pose matrix. However, this approach is limited to describing the current state of the world – one can express neither changes in the object locations over time nor differences between the perceived and an intended world state. This is a strong limitation: Robots would neither be able to describe past nor (predicted) future states, nor could they reason about the effects of actions.
Memory, prediction, and planning, however, are central components of intelligent systems. The reason why the naive approach does not support such qualified statements is the limitation of OWL to binary relations that link exactly two entities. These relations can only express if something is related or not, but cannot qualify these statements by saying that a relation held an hour ago, or is supposed to hold with a certain probability. For this purpose, we need an additional instance in between that links e.g. the object, the location, the time, and the probability.
Pose representation in KnowRob
In KnowRob, these elements are linked by the event that created the respective belief: the perception of an object, an inference process, or the prediction of future states based on projection or simulation. The relation is thus reified, that is, it is transformed into a first-class object. These reified perceptions or inference results are described as instances of subclasses of MentalEvent, for instance VisualPerception or Reasoning.
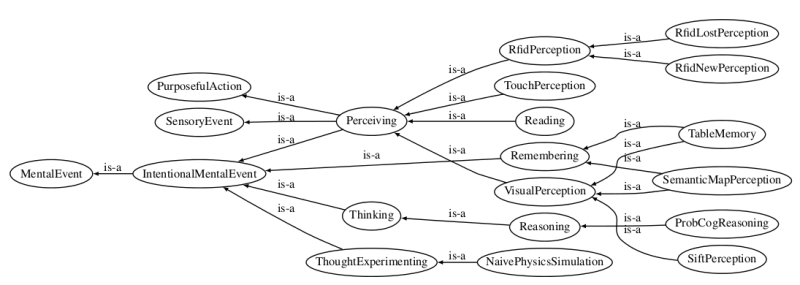
Object recognition algorithms, for instance, are described as sub-classes in the VisualPerception branch. Multiple events can be assigned to one object, describing different detections over time or differences between the current world state and the state to be achieved. The resulting internal representation is visualized below. Based on information from the vision system, KnowRob generates VisualPerception instances that link the object instance icetea2 to the different locations where it is detected over time.
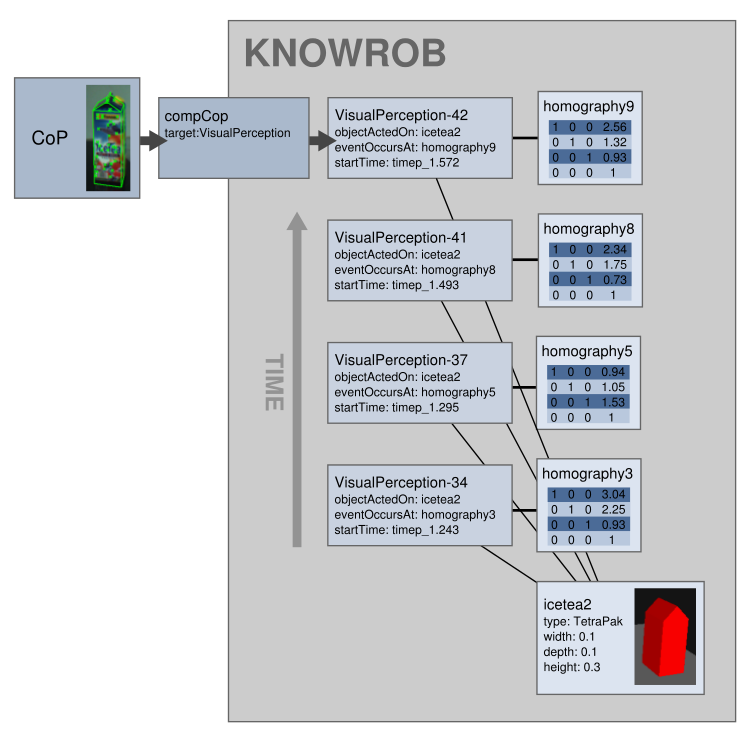
Using this representation, we can describe multiple “possible worlds”, for example the perceived world, a desired world (e.g. created by a planner), or the predicted world state computed by projection methods. All of these states are represented in the same system, which allows possible to compare them, to check for inconsistencies or to derive the required actions. This would be difficult if separate knowledge bases would be used for perceived and inferred world states.
Reasoning about relations between objects at different points in time
The aforementioned representation of object poses using MentalEvents forms the basis for evaluating how qualitative spatial relations between objects change over time. For example, if a robot has to recall where it has seen an object before or which objects have been detected on the table five minutes ago, it has to qualify the spatial relations with the time at which they held. We use the holds(rel(A, B), T) predicate to express that a relation rel between A and B is true at time T. Such a temporally qualified relation requires the description of the relation rel between the objects A and B and the time T, which cannot be expressed in pure description logics. We thus have to resort to reification, for which we use the mental events described earlier. Based on these detections of an object, the system can compute which relations hold at which points in time.
Please refer to Section 3.2.5 in Tenorth,2011 for a detailed discussion how this representation can be used for reasoning about how the (qualitative) relations between objects change over time.
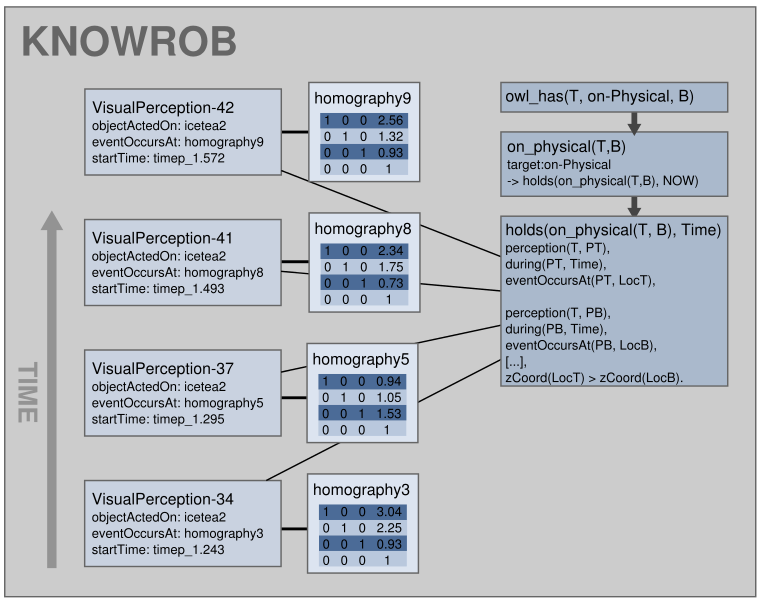
(Text and graphics adapted from Tenorth,2011)