A Formal Model of Affordances for Flexible Robotic Task Execution
In recent years, it has been shown that robotic agents are able to generate human-like behavior for everyday tasks such as preparing a meal, or making a pancake. These demonstrations, while being very impressive, also impose a lot of hard constraints on the environment such that the deployment of, for example, a robotic cook to an arbitrary household is still impossible. The step change is to make it possible to deploy robots to many different environments, and for many different tasks without the need to re-program them. We believe that one of the key aspects towards the achievement of this goal is an abstraction of the interaction between the robotic agent and its environment. Such an abstraction enables the robot to execute plans without hardcoding interaction patterns. This can be achieved through reasoning about object affordances which is the topic of a paper we have submitted to the 24th European Conference on Artificial Intelligence (ECAI 2020) [1].

The affordance term was first introduced by James Gibson in 1979 to describe the interaction of living beings and their environment. He has coined the term as “what the environment offers to the animal, what it provides or furnishes, either for good or ill”. An affordance is not just a property of the environment, it also depends on the agent that must be aware of it, and whether its embodiment is suitable to perform the interaction. However, the scientific community has not reached a consensus on how an affordance should be characterized ontologically. Gibson already acknowledged this by stating that “an affordance is neither an objective property nor a subjective; or it is both if you like. An affordance cuts across the dichotomy of subjective-objective. It is both physical and psychical, yet neither”. A number of different approaches for affordance modeling were proposed in literature, including to characterize them as events or as object qualities. Our work is based on the dispositional object theory proposed by Turvey, in which a disposition of an object (the bearer) can be realized when it meets another suitably disposed object (the trigger) in the right conditions (the background).
Our goal is to enable a robot to answer different types of questions about potential interactions with its environment. One of the questions being ”what can be used for a particular purpose?”. That is, what are the combinations of objects that may interact with each other such that a dedicated goal can be achieved. As an example, a robot cook may need to find a suitable substance that can be used as a thickener for some gravy that would be too thin otherwise. Being able to answer this question is in particular relevant for goal-directed behavior. Another aspect is that a robot may need to explore an unknown environment first. To discover interaction potentials it may ask “what can this be used for?” after it has detected some object, lets say a package of flour where the answer might include that flour can be used as a gravy thickener. Similarly, the robot may ask “what can this be used with?” to discover complementary objects in the environment. That is, for example, that the flour can be used with the gravy. As knowledge about the world is likely to be incomplete, it is also worth considering negative variants of previous questions such as “what cannot be used for a particular purpose?”. These are useful to distinguish between cases where it is explicitly known that an object cannot be used for some purpose from cases where it is unknown.
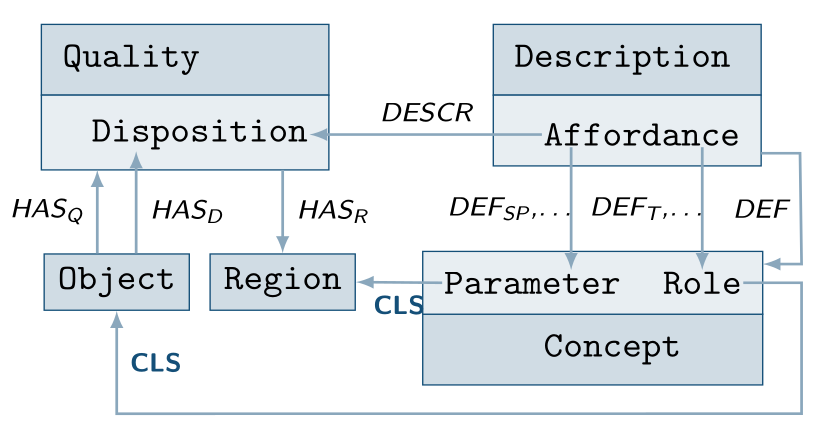
Turvey interprets a disposition as the property of an object that is a potential. Consequently we define in our theory that a disposition is a property of an object that can enable an agent to perform a certain task. Dispositions are seen as absolute properties that are not dependent on context, and which are implied by the existence of the object that hosts them. We further say that a dispositional match is a potential of interaction between bearer and trigger of some disposition. This is that two objects are complementary to each other with respect to some task, such as the flour and gravy from earlier example that form a dispositional match for the task of thickening gravy, or a valve with a diameter huge enough to serve as hiding spot for some agent as displayed on this slide. The affordance term is then defined as a description that conceptualizes a dispositional match. Hence, the name descriptive affordance theory. The notion of description is derived from the upper-level model that we use, which is partly based on the Descritpion and Situation ontology. The pattern is that concepts defined in descriptions are used to classify entities within situations that satisfy the description. We say that the manifestation of an affordance is a situation that satisfies the conceptualization of a dispositional match. Meaning that an action was performed that executes the afforded task with appropriate objects that have a dispositional match taking roles during that action.
[1] Daniel Beßler, Robert Porzel, Pomarlan Mihai, Michael Beetz, Rainer Malaka, John Bateman,
"A Formal Model of Affordances for Flexible Robotic Task Execution",
In: Proceedings of the 24th European Conference on Artificial Intelligence (ECAI), 2020.
KnowRob Development in CRC EASE
The Institute for Artificial Intelligence (IAI), led by Prof. Michael Beetz at the University of Bremen, is leading the Collaborative Research Center (CRC) Everyday Activity Science and Engineering (EASE), funded by the German Research Foundation (DFG). EASE is an interdisciplinary research centre at the University of Bremen. Its core purpose is to advance our understanding of how human-scale manipulation tasks can be mastered by robotic agents. To achieve this, EASE establishes the research area Everyday Activity Science and Engineering and creates a research community that conducts open research, open training, open data, and knowledge sharing. In-depth information on EASE research can be found on the website.

EASE is composed of multiple phases. The current phase is the first phase where the focus is on what is called narrative enabled episode memories (NEEMs). NEEMs can be best envisioned as a very detailed story about an experience. The story contains a narrative of what happened, but, in addition, low-level data that represents how it felt to make this experience. The latter case is realized by storing huge amounts of sensor data that is coupled with the narrative through time indexing. The representation of such experiential knowledge is key when statistical models are to be trained that generalize over the highly situation depended information contained in NEEMs. The second phase, which supposedly starts in 2022, will focus more on the generalization of acquired NEEMs.
OWL-enabled Plan Generation at AAMAS 2018
KnowRob developers have presented their work on OWL-enabled plan generation for assembly activities at AAMAS'18 in Stockholm [1], and have received a best paper nomination for their work. The rational of the contribution is to describe, in an ontology, what the goal of an assembly activity is in terms of what assemblages need to be created from what parts, how the parts connect to each other, and how the robot can interact with them. This model of a final product is compared with what the robot knows about its current situation, what parts are available, and in what assemblages they contribute. The belief state is represented as ABox ontology, and KnowRob detects what information is not yet grounded or inconsistent with respect to the model of the final assemblage to decide what steps are still needed to create a complete assemblage from scattered parts available.
[1] Daniel Beßler, Mihai Pomarlan, Michael Beetz,
"OWL-enabled Assembly Planning for Robotic Agents",
In: Proceedings of the 2018 International Conference on Autonomous Agents, Stockholm, Sweden, 2018.
KnowRob at ICRA 2018
We are proud to announce that the second generation of the KnowRob has been presented at ICRA'18 in Brisbane Australia.
KnowRob was first introduced in 2009 [1] where Tenorth and Beetz argue that autonomous robot control demands KR&R systems that address several aspects that are commonly not sufficiently considered in AI KR&R systems, such as that robots need a more fine-grained action representation. This was pointed out early by Tenorth and Beetz [2] when they argued that service robots should be able to cope with (often) shallow and symbolic instructions, and to fill in the gaps to generate detailed, grounded, and (often) real-valued information needed for execution.
We have introduced the second generation of the KnowRob system at ICRA'18 [3] where the focus of development has shifted towards the integration of simulation and rendering techniques into a hybrid knowledge processing architecture. The rational is to re-use components of the control program in virtual environments with physics and almost photorealistic rendering, and to acquire experiential knowledge from these sources. Experiential knowledge, called narrative enabled episodic memory in KnowRob, is used to draw conclusions about what action parametrization is likely to succeed in the real world (e.g., through learning methods) – this principle is inspired by the simulation theory of cognition [4].
The architecture blueprint for KnowRob 2.0 is depicted below.
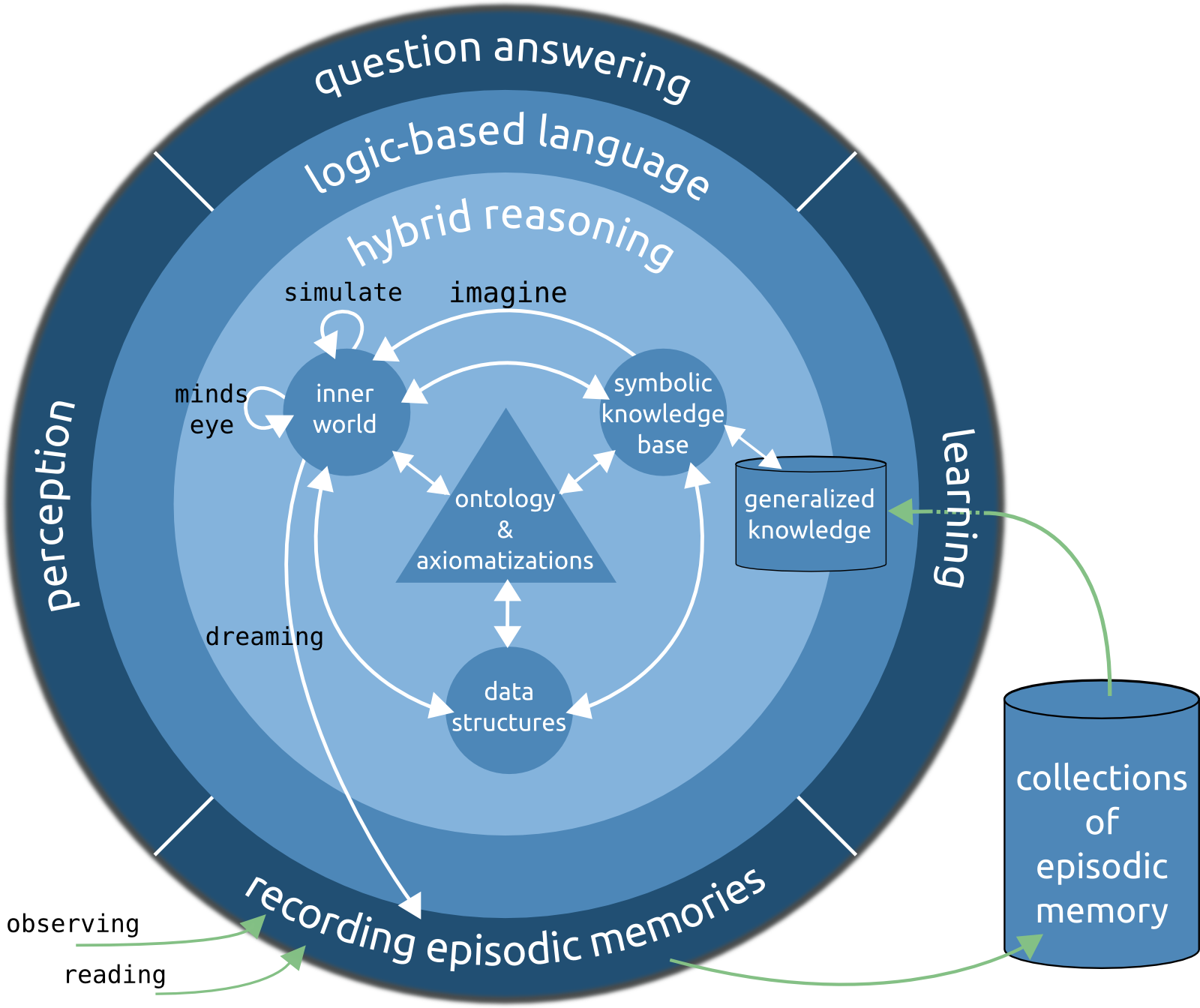
Displayed components exist at least prototypically, and will be elaborated more in future publications.
[1] Moritz Tenorth, Michael Beetz,
"KnowRob – knowledge processing for autonomous personal robots",
In: IEEE/RSJ International Conference on Intelligent Robots and Systems, IEEE, pp. 4261–4266, 2009.
[2] Moritz Tenorth, Michael Beetz,
"Representations for robot knowledge in the KnowRob framework",
In: Artificial Intelligence, Elsevier, 2015.
[3] Michael Beetz, Daniel Beßler, Andrei Haidu, et al.,
"KnowRob 2.0 – A 2nd Generation Knowledge Processing Framework for Cognition-enabled Robotic Agents".
In: International Conference on Robotics and Automation (ICRA), 2018.
[4] Germund Hesslow,
"The current status of the simulation theory of cognition",
In: Brain Research 1428, pp. 71–79, 2012.
KnowRob GitHub repository structure
The catkinized KnowRob version is used by the IAI group in Bremen for more then 6 months. For this summer, we plan the next KnowRob release based on the catkinized version that proved to be stable in the last months.
The development was done in the 'indigo-devel' branch at GitHub while the 'master' branch contained the rosws-based KnowRob version. In order to avoid confusion, we decided to restructure the GitHub repository so that the code is actively developed in the master branch again with different branches for different supported ROS versions. The old 'master' branch has moved to a new branch 'groovy'. Note that this KnowRob version is not actively developed anymore. The old 'indigo-devel' branch has moved to the 'master' branch. Additionally, we mirrored the new 'master' branch to new branches 'hydro' and 'indigo' which contain the latest stable snapshot for the corresponding ROS version.